At Samaya AI, we build deep research systems for complex questions that require exploring thousands of sources and reasoning over long search trajectories. Working with researchers from Princeton University, we found that existing frameworks struggle with a fundamental problem: more than 50% of search trajectories fail due to poor context management on public benchmarks. These frameworks flood the LLM context with irrelevant information that ultimately derails the search process. Our proposed method—SLIM—decouples search and browsing while using periodic summarization to compress search trajectories. SLIM outperforms existing frameworks while using only 15-25% of the tool calls and reduces hallucination by 2.5 times. We also release the paper and code with detailed results and reproducible experiments.
Imagine this: You are a financial analyst with 30 minutes to answer a complex question that could influence a million-dollar investment decision. The question isn’t simple - it requires digging through hundreds of earnings calls, SEC filings, press releases and news articles to piece together a comprehensive answer.
This is the reality many of our customers face daily.

Figure 1: An example complex financial query that requires long-horizon search over many sources
A system that can answer such questions needs to explore thousands of relevant documents and web pages, filter and synthesize information from multiple sources, and reason over long trajectories of searches. This is long-horizon agentic search, and it is the foundation for powerful applications like deep research systems. Despite recent advances, even sophisticated open-source frameworks struggle with these tasks and are unsuitable for complex financial workflows.
Our analysis revealed a fundamental problem: context limitations. Current systems accumulate long, noisy content that quickly fills their context windows–think of it as the system’s working memory–causing them to either hit token limits, exhaust their tool budgets, or stop prematurely. They get lost in the maze.
We developed SLIM (Simple Lightweight Information Management)—a long-horizon search framework built on three core principles (as shown in Figure 2):
1. Decoupled Search and Browse Tools
Unlike traditional systems that fetch full content for all search results, SLIM's search tool returns only titles, URLs, and short snippets. The LLM can then selectively use a separate browse tool to dive deeper into promising pages based on their relevance. This simple separation dramatically reduces noise and unnecessary tool calls.
2. Selective content extraction
When browsing, SLIM doesn't return entire web pages. Instead, it identifies and returns only the most relevant section matching the query—keeping context concise while preserving useful information.
3. Periodic Summarization of Search Trajectory
As trajectories grow longer, SLIM manages its own memory by periodically compressing the entire search trajectory. This differs from existing systems that summarize retrieved pages, and acts as a general-purpose context manager, allowing the system to scale to much longer searches while maintaining clarity.
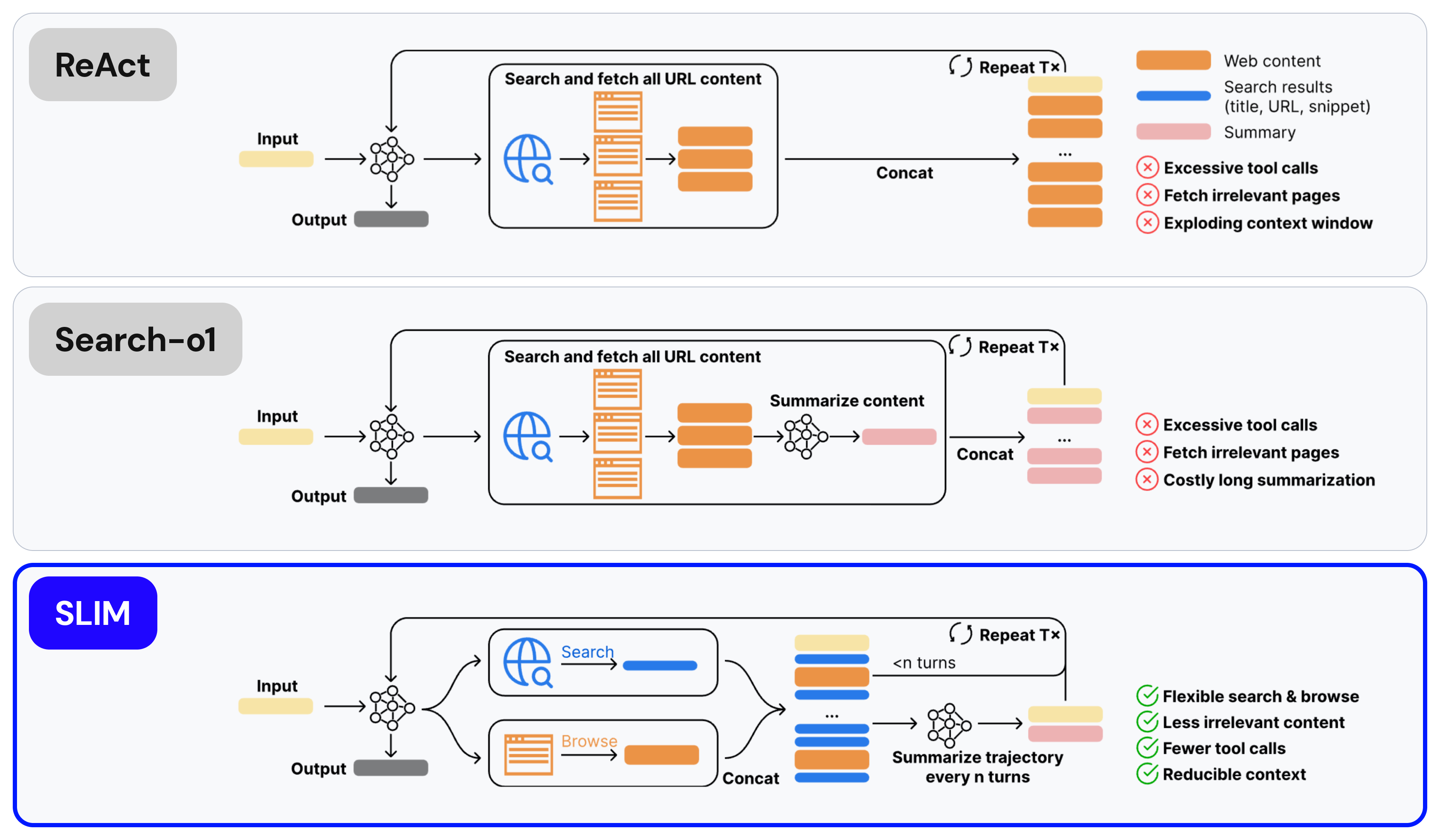
Figure 2: SLIM's cooperation between search, browse, and summarization modules keeps context concise compared to existing frameworks.
Other existing frameworks like ReAct and Search-o1 bundle search and browsing into a single operation—retrieving full content from every search result, regardless of relevance leading to context pollution. Our method overcomes these limitations.
We evaluated SLIM against leading long-horizon search frameworks on two challenging public benchmarks: BrowseComp (requiring exhaustive web exploration) and Humanity's Last Exam (HLE, testing domain-specific search and reasoning).

Figure 3: Example queries and answers from BrowseComp and Humanity’s Last Exam (HLE) datasets.
Through extensive experiments, we found:
SLIM outperforms existing long-horizon search systems. Figure 4 presents SLIM’s performance on BrowseComp and HLE datasets using GPT-o3 as the base model. The same trend is also observed using other models, such as GPT-o4-mini and Claude Sonnet-4.5, highlighting SLIM’s general advantages.

Figure 4: Performance of SLIM compared to other systems on BrowseComp and HLE datasets.
SLIM achieves superior performance with significantly fewer tool calls and lower costs. Notably, SLIM only uses 15-25% of the tool calls compared to the second best system (Search-o1) and incurs much lower overall costs. Figure 5 presents how SLIM compares to other systems in terms of tool calls and LLM token usage costs.
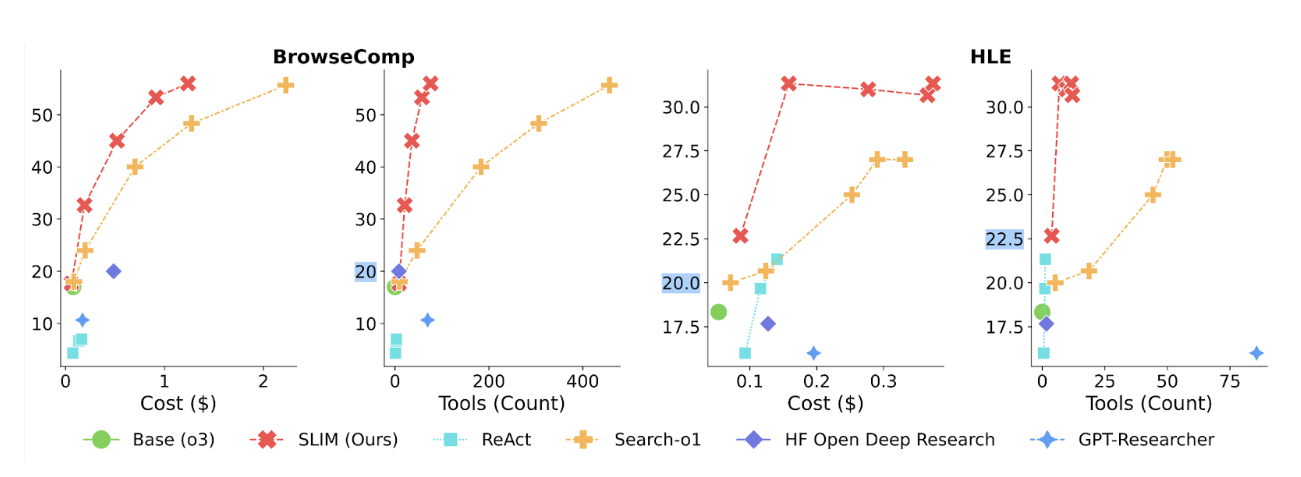
Figure 5: Accuracy vs. tool calls and costs on both datasets.
SLIM dramatically reduces hallucination. To understand why SLIM succeeds, we developed an automated trajectory analysis pipeline. Our analysis revealed that existing systems overly rely on their parametric knowledge and hallucinate answers that were unsupported by the search trajectory. For example, Search-o1, exhibits the lowest hallucination rate of all existing systems at 47%. With SLIM, we reduced it to 19%.
This efficiency comes from SLIM's careful information management—it adds only relevant content to context and minimizes noise, allowing the underlying LLM to reason more effectively.
SLIM demonstrates that simpler can be better. While the community has gravitated toward increasingly complex multi-agent orchestration, our work shows that careful tool design and context management can achieve more effective exploration and superior results in long-horizon search systems, while incurring much lower cost. We incorporated these findings into Samaya’s finance-specific deep research agents and found clear improvements.
Further, our automated trajectory analysis pipeline is useful for the community to zoom into the failure modes of existing systems, shedding lights for future development. In practice, we use a similar trajectory analysis pipeline at Samaya to find common failure modes and remedy them.
The following resources are made available:
Howard Yen led this research work during his internship at Samaya AI, under the mentorship of Yuhao Zhang, Ashwin Paranjape, Jack Hessel and Thejas Venkatesh, together with guidance from Danqi Chen and Mengzhou Xia from Princeton University.
Special thanks to members of the Samaya team, including Bram Mulders, Kyle Chang, Lina Fowler, Skyler Hallinan for their assistance, and members of the Princeton Natural Language Processing Group, including Yoonsang Lee, Xi Ye, Adithya Bhaskar, Jeff Cheng, Lucy He, Xingyu Fu, Tianyu Gao, and others—for their helpful discussions and feedback.
Experience how Samaya can supercharge financial workflows
Get a DemoWe're backed by Gen AI leaders
The Expert AI Agent Platform Defining
Modern Finance
© 2026 Samaya AI. All Rights Reserved.


"We’ve spoken to ~40 companies offering AI in finance solutions, and done pilots with 10-15. Yours is the only tool that analysts are actively asking for, and saying how useful they find it."
Top 5 Hedge Fund