In this post, we put forward some (possibly controversial) perspectives on this next evolution of the AI ecosystem.
The start of the GenAI wave was driven by a belief that there would be an “oligopoly” of foundation model builders, who would capture all the value of AI.
Fast forward ~22 months, and while there is clear consolidation in the development of the largest models, value capture is far more distributed, and still largely emerging! With the vibrant open source ecosystem, and API access to closed source models, it’s becoming clear that foundation models are more the infrastructure, not the end to end applications — being built for everyone also means being adapted to no one.
We predict that foundation models:
As we see this evolution from foundation models to AI products, from infrastructure to applications, we believe that AI training will continue to be a key differentiator between the best AIs and the rest.
This training might comprise of finetuning the foundation model itself, complex multistage post-training of open source models (e.g. training on different tasks, domains or feedback), co-adaptive training of multiple AI models forming a compound AI system, and more.
(Note in line with the consolidation, we expect standard next token pretraining on internet data to commoditize, replacing the random initialization start of neural network training. Continued pretraining may play a key part in future best AIs.)
Why is this?
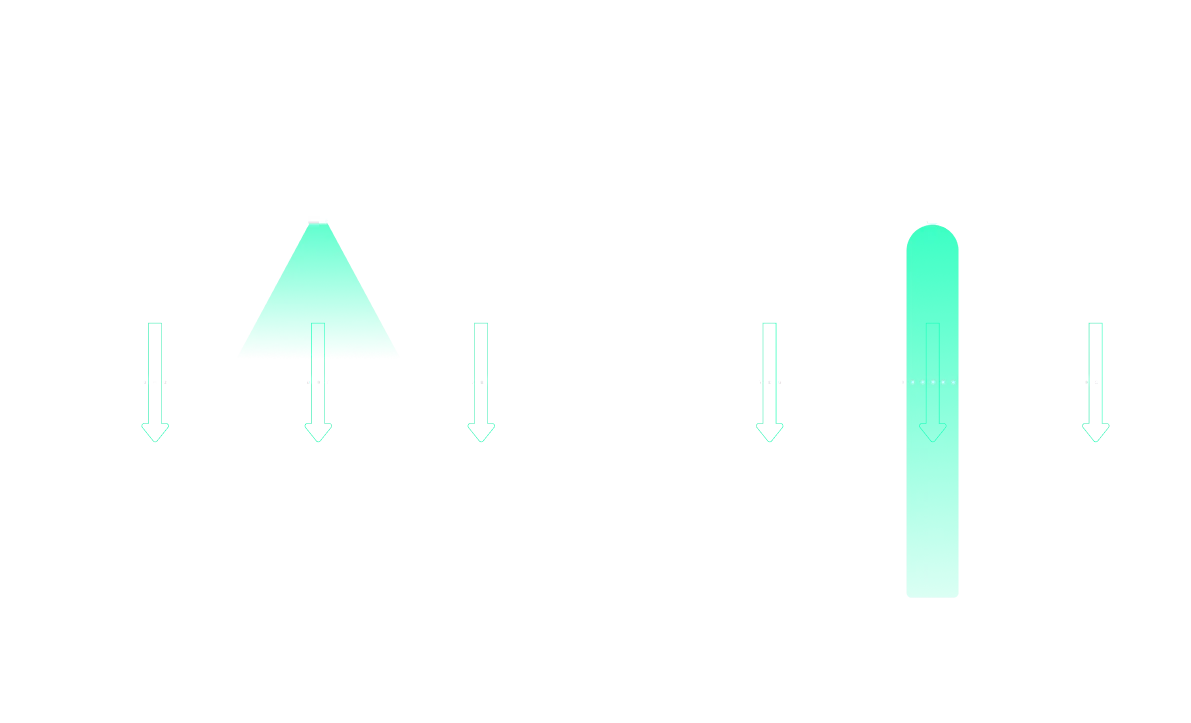
Figure 1: If Prompting is a Flashlight, Training is a Laser Beam
Today’s AI models can learn many different capabilities. Some of these capabilities are simple, or well represented in the training data and training process of the model (i.e. model is trained on related tasks or prompts). Prompting can then be used to make the model successfully express this capability. Like a flashlight, prompting is broad and multi-purpose, and can be versatile in getting AI models to express capabilities made accessible through training.
But when the AI must express capabilities very different to what it has seen during training, prompting is often unreliable with poor performance. This is where training becomes crucial. Like a laser beam, training is powerful and precisely controllable for learning complex new tasks.
One recent example of the power of training (and careful AI design), is seen in AlphaProof and AlphaGeometry, which together achieved a silver medal on the International Mathematical Olympiad. Similar results are seen in the recent Llama 3 paper demonstrating the importance of post-training for capabilities like tool use of the Wolfram Alpha API, python interpreter, and search engines.
Yet another example is seen in code applications, with the best code models trained on enormous amounts of code data, and more specialized AI systems built out to support a number of complex software engineering tasks such codebase wise refactoring, editing, etc.
Perhaps the best example of the power of training is given by ChatGPT itself!
Historically, we saw ChatGPT released in late 2022, kicking off the Generative AI wave. But the model powering chatGPT, GPT-3, was released in summer 2020. What changed in this time?
The biggest development was the use of RLHF to post-train GPT-3 to be more conversational! OpenAI carefully collected instructions and conversational snippets and used this to teach GPT-3 how to be an engaging chatbot, creating chatGPT! This is now such an established training practice, that most open source AI model releases consist of a “base” pretrained model, and a “chat” (instruction + preference post trained) model!
Most recently, the release of o1 provides another example of this, where OpenAI explicitly (post)trained the model with RLHF to follow chains of thoughts and expand its problem solving capabilities. We predict that this will become a standard type of post-training on base pretraining, and future model releases will see “chat” and “reasoning” versions.
Amara’s law says
“People overestimate technology’s impact in the short term, and underestimate the impact in the long term.”
We are seeing this happen in real-time with AI, where the initial hype on raw model training has diminished, just as the long term possibilities of AIs that can automate entire workflows — a sequence of tasks that users want to carry out — comes into sight.
For example, imagine the ultimate shopping assistant that can anticipate your shopping needs, draw inspiration from social media, and browse different stores globally to find the best products at the best price — without you ever instructing it. Or a coding agent so powerful, it’s like a team of expert programmers working together to architect and execute a complex software engineering project. Or, the vision of Samaya, which is a knowledge AI so powerful it can autonomously synthesize new discoveries and push the boundaries of human knowledge creation.
This vision of the future is inspiring the development of “AI Agents”. The vast majority of these today are built through multiple prompt calls to foundation models. But because prompting is less reliable, and the target application is workflows (sequence of tasks), each task introduces an error rate, and errors compound through the sequence of tasks. For example imagine a document extraction AI which has 90% accuracy in pulling out key numbers and text correctly. If this document extraction AI must be called 10 times by a document AI agent to aggregate all the information and form conclusions, this agent has only ~35% accuracy! This makes it difficult for today’s AI agents to reliably tackle complex workflows.
This is the key question of our times, and consistent with our prior posts, we believe the answer to be no. There are many reasons for this:
For this reason, we predict most of the best future AIs will be built “brick by brick”, designed and trained for highly sophisticated workflows.
We’ve seen this in our first-hand experience building Samaya AI, an AI Knowledge Agent for human knowledge discovery and creation in expert verticals like financial services. Over many months of development, Samaya’s AI has been built out “brick by brick” to support more and more complex workflows.
The first layer of AI capabilities are on performing high quality retrieval and summarization for specific domain questions. These became a core subroutine in an AI knowledge agent that is able to take complex instructions (e.g. produce a report analyzing new market trends), plan out the individual tasks, execute, and produce the final result. The high accuracy of the lower layer capabilities are crucial in avoiding compounding errors and provide high quality outputs. In the future, we’ll be equipping the AI with stronger contextualized reasoning capabilities, allowing it to anticipate and execute even more complex workflow tasks.
We also see this brick by brick structure in products like self-driving cars (base layer capabilities of visual + sensor perception called by higher layers of driving action planning) and AI for code (base layer capabilities of code completion called by codebase aware sequential editing).
A general picture of this “brick by brick” structure might look like the following:

Figure 2: Layering of AI capabilities.
This shows multiple layers of AI capabilities. Each layer of capabilities is a compound AI system of multiple models, API calls, tools etc. E.g. for Samaya the first layer would be retrieval and summarization, while for self-driving it might be scene segmentation. Higher layers call lower layers like subroutines, e.g. for self-driving, a particular action (turning) might require multiple calls of scene segmentation, which inform the output of the higher layer. We see each new layer as increasing the scope and complexity of the workflows the AI can perform.
The best AIs are yet to come. They will be constructed brick by (painstaking!) brick. And they’ll be diversely designed, trained and closely tied to complex, valuable workflows. General purpose foundation models will be one part of the infrastructure for these AIs, and also see close coupling with cloud providers and consumer products.4
Thanks to many people who read earlier versions of this post. Special thanks to Matei Zaharia, Jeff Dean, David Cahn and Reid Hoffman for detailed feedback.
Thanks also to Samy Bengio, Yann LeCun, Sasha Rush, Hugo Larochelle, Marty Chavez, Ben Horowitz, Ram Shriram, Vinod Khosla, Nathan Beniach, Joe Horowitz, Vijay Reddy, Aaron Sisto, Manish Kothari, Jack Hessel, Alessandro Spinosi, Ashwin Paranjape, Christos Baziotis, Nelson Liu, Otavio Good and Robert Nishihara for comments and feedback.
Experience how Samaya can supercharge financial workflows
Get a DemoWe're backed by Gen AI leaders
The Expert AI Agent Platform Defining
Modern Finance
© 2026 Samaya AI. All Rights Reserved.


"We’ve spoken to ~40 companies offering AI in finance solutions, and done pilots with 10-15. Yours is the only tool that analysts are actively asking for, and saying how useful they find it."
Top 5 Hedge Fund