Information overload: the challenges of expanding context windows in large language models
![]() Nelson Liu
Nelson Liu ![]() Ashwin Paranjape
Ashwin Paranjape ![]() Michele Bevilacqua
Michele Bevilacqua ![]() Fabio Petroni
Fabio Petroni ![]() Maithra Raghu
Maithra Raghu
Language models have demonstrated impressive performance for a variety of applications and use-cases, but limitations remain—for example, it is difficult to add knowledge beyond their pre-training knowledge cut-off, and they may generate factually incorrect statements. Overcoming these shortcomings requires incorporating external knowledge into language models.
The predominant current approach to incorporate external knowledge into language models is to use retrieval augmentation, where a retrieval system (e.g., a commercial search engine like Google) is used to fetch relevant and up-to-date knowledge for the language model to use. This enables language models to use knowledge beyond what’s seen during training.
A different approach to augmenting language models with knowledge beyond its training comes from expanding their context windows — increasing the number of words (tokens) that the language model can use as input. The state-of-the-art language models of 3 years ago had context windows of 2048 tokens (e.g. GPT-3; text-davinci-001). In the last few months however, context windows have increased by an order of magnitude: MosaicML released MPT-30B, an open-source model that supports 8K tokens, OpenAI released its extended-context GPT-3.5-Turbo 16K, and Anthropic’s Claude supports input contexts of up to 100K tokens.
In principle, longer context windows provide an appealing and simple alternative to retrieval-based augmentation—instead of using and maintaining a retrieval system, you might be able to fit all relevant knowledge into the language model’s input context, giving it access to all available knowledge. Even though the language model has all this knowledge, is it able to use all this knowledge when prompted to solve downstream tasks?
We address this question in our recent study, Lost in the Middle: How Language Models Use Long Contexts. This study evaluates whether long-context language models can robustly use knowledge in lengthy input contexts. We find that language model performance is highest when relevant knowledge occurs at the very start or end of long input contexts, and significantly degrades when models are forced to use knowledge in the middle of the context. These results indicate that current language models do not effectively use their entire context, and that retrieval is still a crucial ingredient for effectively augmenting language models with external knowledge.
Measuring how language models use their input context
To measure how language models use their input context, we evaluate their performance on multi-document question answering: given a user question and several relevant documents (exactly one of which contains the answer), the model is tasked with answering the user question. The figure below provides an example.
Input Context:
Write a high-quality answer for the given question using only the provided search results (some of which might be irrelevant).
Document [1] (Title: Asian Americans in science and technology) Prize in physics for discovery of the subatomic particle J/ψ. Subrahmanyan Chandrasekhar shared…
Document [2] (Title: List of Nobel laureates in Physics) The first Nobel Prize in Physics was awarded in 1901 to Wilhelm Conrad Röntgen, of Germany, who received…
Document [3] (Title: Scientist) and pursued through a unique method, was essentially in place. Ramón y Cajal won the Nobel Prize in 1906 for his remarkable…
Question: who got the first nobel prize in physics
Answer:
Desired Answer:
Wilhelm Wilhelm Röntgen
Figure 1: Example of the multi-document question answering task, with an input context and the desired model answer. The relevant document for correctly answering the request is bolded within the input context (number 2).
In particular, we study how model performance is affected by the position of relevant knowledge in the input context by changing the position of the document that contains the answer. For example, if we give the model a query and 20 documents, we can either place the document that contains the answer at the very start of the context (i.e., 1st position), in the middle (the 10th position), or at the end (the 20th position). If models are able to properly use all of their context, we expect that changing the location of the document that contains the answer should not affect the performance—the model should achieve high performance regardless of if the relevant document occurs first, in the middle, or last.
Input Context:
Write a high-quality answer for the given question using only the provided search results (some of which might be irrelevant).
Document [1](Title: List of Nobel laureates in Physics) The first Nobel Prize in Physics was awarded in 1901 to Wilhelm Conrad Röntgen, of Germany, who received…
Document [2](Title: Asian Americans in science and technology) Prize in physics for discovery of the subatomic particle J/ψ. Subrahmanyan Chandrasekhar shared…
Document [3](Title: Scientist) and pursued through a unique method, was essentially in place. Ramón y Cajal won the Nobel Prize in 1906 for his remarkable…
Question: who got the first nobel prize in physics
Answer:
Desired Answer:
Wilhelm Wilhelm Röntgen
Figure 2: Modulating the position of relevant knowledge within the input context for the multi-document question answering example presented in Figure 2. Reordering the documents in the input context does not affect the desired output. The relevant document for correctly answering the request is bolded within the input context (number 1).
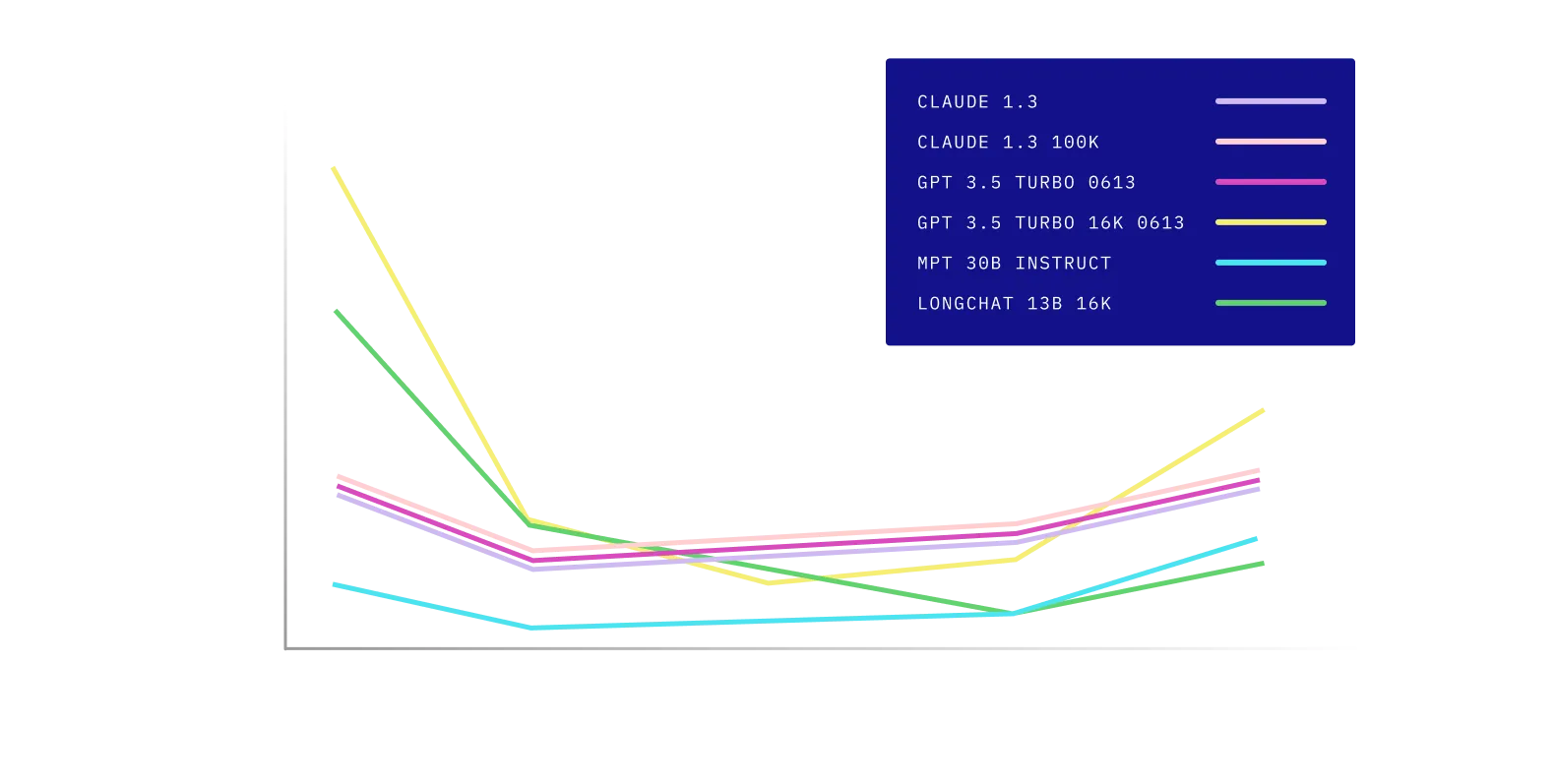
Our results (illustrated below; Figure 3) show that model performance is substantially affected by the position of relevant knowledge (the document that contains the answer) in the input context. GPT-3.5-Turbo has the largest accuracy degradation; its performance drops by more than 20% when the document containing the answer is moved from the front of the context (1st position) to the middle (10th position). These results indicate that current language models fail to robustly use long input contexts when prompted for downstream tasks.
What’s next?
These findings are at the core of our work at Samaya AI, where we are developing a cutting-edge platform for knowledge discovery and expert reasoning. We’re exploring several directions related to these results—improving language models’ abilities to reason over complex external information and how to effectively use them for knowledge retrieval and discovery. If you are interested in pushing the boundaries of LLM and knowledge, get in touch at at [email protected]!
Read the full paper: Lost in the Middle: How Language Models Use Long Contexts Get the code: github.com/nelson-liu/lost-in-the-middle