Evaluation of AI Agents at Samaya
![]() Jack Hessel
Jack Hessel
Samaya is developing AI agents that dynamically compose models (e.g., retrievers, named entity disambiguators) to tackle challenging knowledge tasks that exceed the capabilities of any single component. Beyond traditional evaluations — which typically assess components individually — we are creating a set of evaluation environments designed to measure agent performance in realistic, holistic, and ambitious scenarios.
In this blog post, we’ll highlight one evaluation environment that we developed: RealityBench. We’ll see that:
- Samaya-QA, our real-time question answering agent which itself orchestrates a composition of models, outperforms baselines like Grounded RAG+Claude Sonnet; and
- Samaya-QAx16, an agent that scales compute by 16x compared to Samaya-QA, performs even better, exhibiting promising scaling properties.
RealityBench: Can Models Reason About the Future?
Users of Samaya often conduct research with the goal of forecasting key performance indicators (for companies, for economies, etc.). As a proxy, we built RealityBench: an evaluation that assesses whether or not our system can itself produce accurate forecasts.
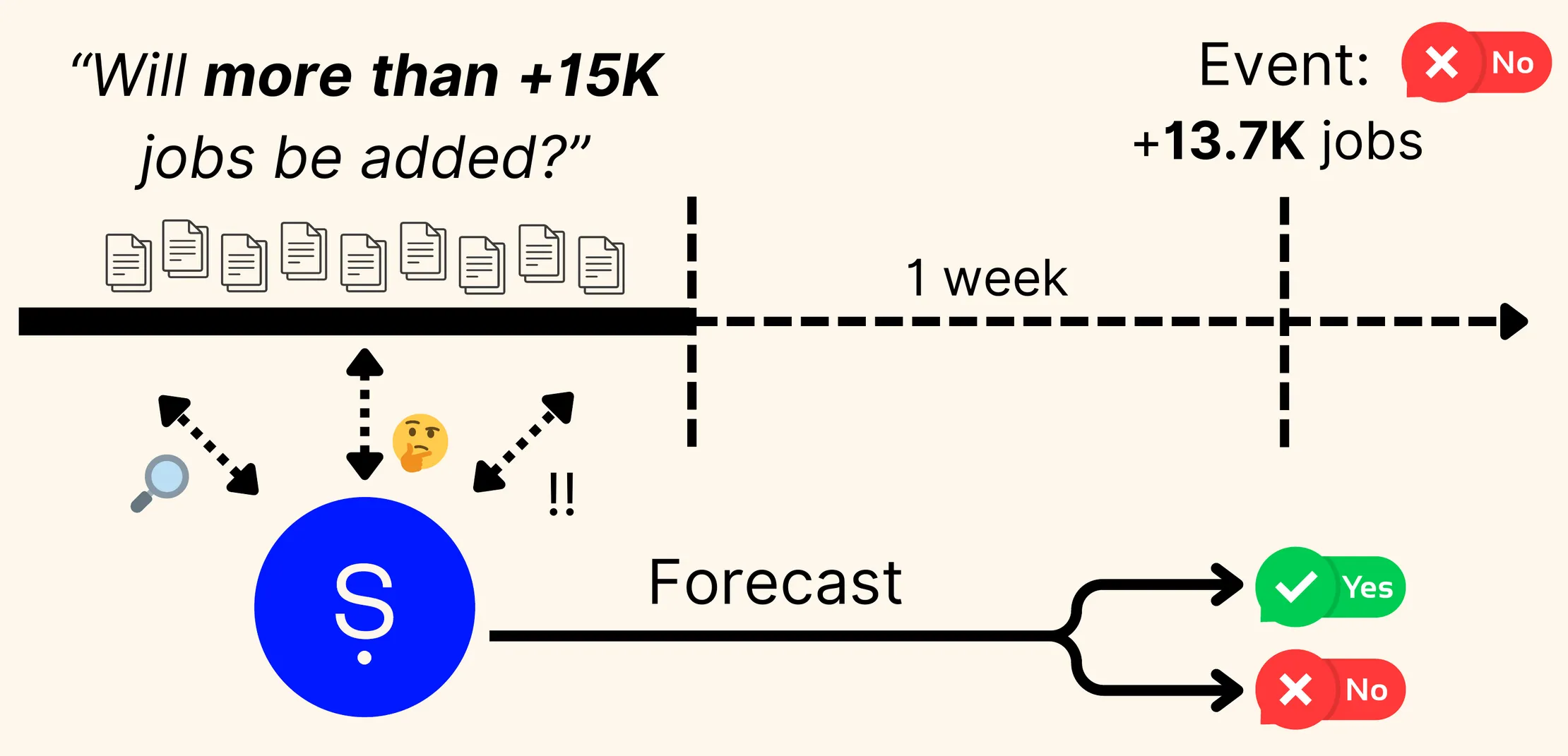
RealityBench consists of 972 timestamped numerical announcements, for example:
On February 7, 2025, the Bureau of Labor Statistics (BLS) reported that employment in the ‘computer systems design and related services’ sector increased by 13.7K jobs.”
We convert announcements into prediction instances by applying a small amount of random noise to the ground-truth quantity (e.g., 13.7K -> 15K), and asking agents to make a binary prediction about the value, i.e.,
True or False: the February 7, 2025 BLS report will report more than +15K jobs in the ‘computer systems design and related services’ sector” (False)
To test forecasting capacity, agents are only given access to documents/information published 1 week before the announcement, e.g., in our running example: all documents available before February 1st, 2025. Binary accuracy is the final metric: random guessing achieves 50%.
Results
We compare the performance of:
- a zero-shot application of claude-sonnet-3.5 v2;1
- Grounded RAG;2
- Samaya-QA --- our real-time question-answering offering; and
- Samaya-QAx16: an agent that is given access to Samaya-QA as a tool, with a budget of 16 queries.
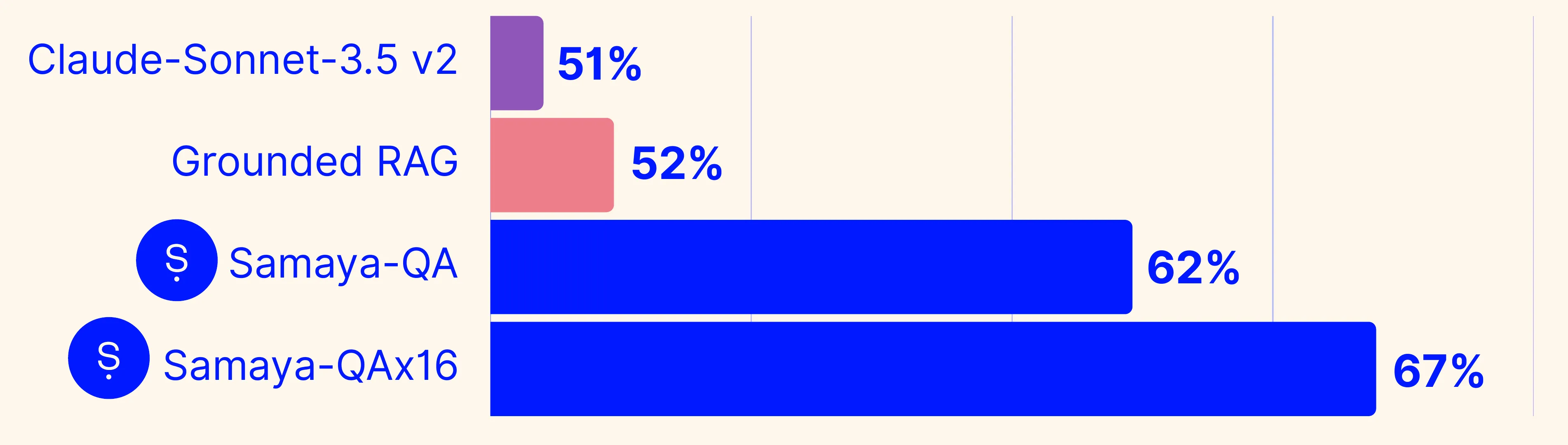
Overall, the results demonstrate that:
- models can meaningfully reason about the future given data from the past;
- Samaya-QA outperforms baselines; and
- providing higher compute budgets (i.e., moving from Samaya-QA -> Samaya-QAx16) demonstrates promising scaling properties.
We qualitatively examine the reasoning traces of Samaya-QAx16, and find that they are interpretable, e.g., for claims like the BLS example above, Samaya-QAx16 makes a calibrated prediction about the employment statistic by organizing its process into a “bear” and “bull” case; researching recent industry trends/conditions; investigating announcements, updates, and commentary from major players; and finally, integrating its findings into a well-formatted and succinct summary.
Samaya-QAx16 is one of several agents we offer on the Samaya platform today!
Scaling Agents beyond RealityBench
We have observed promising scaling properties of Samaya-QAx16 on evaluation environments beyond RealityBench as well. In a future blog post, we will discuss the details of CriteriaEval, which measures domain-specific question answering and search performance by leveraging a set of expert-curated annotations. Here’s a teaser, illustrating similar scaling trends (higher=better).

Stay tuned for more! 😎
Contributors
Jack led the development of RealityBench, ran the experiments, and wrote this blog with feedback from Ashwin Paranjape and Yuhao Zhang.
Varun Patel and Jack worked together to bring Samaya-QAx16 into production.
Special thanks to Yuhao Zhang, Thejas Venkatesh, Christos Baziotis, Alexander Baranov, Ashwin Paranjape, Maithra Raghu, Michele Bevilaqua, Sachin Raj, Suharsh Sivakumar, Fabio Petroni, and Roberto Dessi for their valuable discussions and feedback.
Footnotes
[1] We ask claude-sonnet-3.5 v2 to make a prediction based on its commonsense understanding of the world, and knowledge of past events. All RealityBench instances were mined more recently than the training data cutoff of all component models of all systems, including claude-sonnet-3.5 v2, so it’s unlikely that models have simply memorized these facts.
[2] The Grounded RAG baseline is: an e5-base retriever, a proprietary samaya reranker, and claude-sonnet-3.5 v2 to generate an answer to the question given retrieved results. The final prompt is “grounded” in that it asks the model to cite claims/facts from the given search results.