Promptriever: Elevating Retrieval Models with Instruction-Following Capabilities
At Samaya AI, our customers ask complex financial queries to quickly find accurate and comprehensive information. To support such complex financial workflows, we need retrieval systems that can precisely understand the subtle details in user queries. In collaboration with researchers from Johns Hopkins University, we created Promptriever, the first retrieval model built to handle complex queries with detailed instructions, and published our research at ICLR 2025.
In this blog post, we share insights into how Promptriever was created, highlight key findings from our experiments, and provide links to additional resources that help you explore further.
In a nutshell, modern retrieval models work by encoding both the user query and candidate passages into vector representations, and subsequently scoring the candidate passages based on their similarity to the query vector. Today’s retrieval models are primarily trained with short, simple web search queries, and as a result, they rely on keyword matching or shallow semantic associations to find the relevant passages.

Figure 1: Examples of a regular query and a real-world financial query with detailed instructions covering various aspects of information need.
However, real-world financial queries are intricate. As illustrated in Figure 1 here, these queries are a lot more complex compared to typical web searches, and contain detailed instructions covering time ranges, industry constraints, definitions of relevance, etc. As a result, today’s off-the-shelf retrieval models yield many irrelevant results, forcing users to repeatedly refine their own queries – a process that quickly becomes frustrating and inefficient.
To solve this problem, with Promptriever we enhance retrieval models with substantial instruction-following capabilities to better understand the subtleties and nuances in user queries.
Promptriever is built on a bi-encoder architecture where the same model is used to encode both the query as well as the passages. For advanced understanding capabilities, Prompteriever uses a large language model (LLM) like the open-weights LLaMA model as its backbone. We trained Promptriever on a retrieval dataset augmented with long instructions, allowing it to adapt its definition of relevance based on detailed natural language prompts.
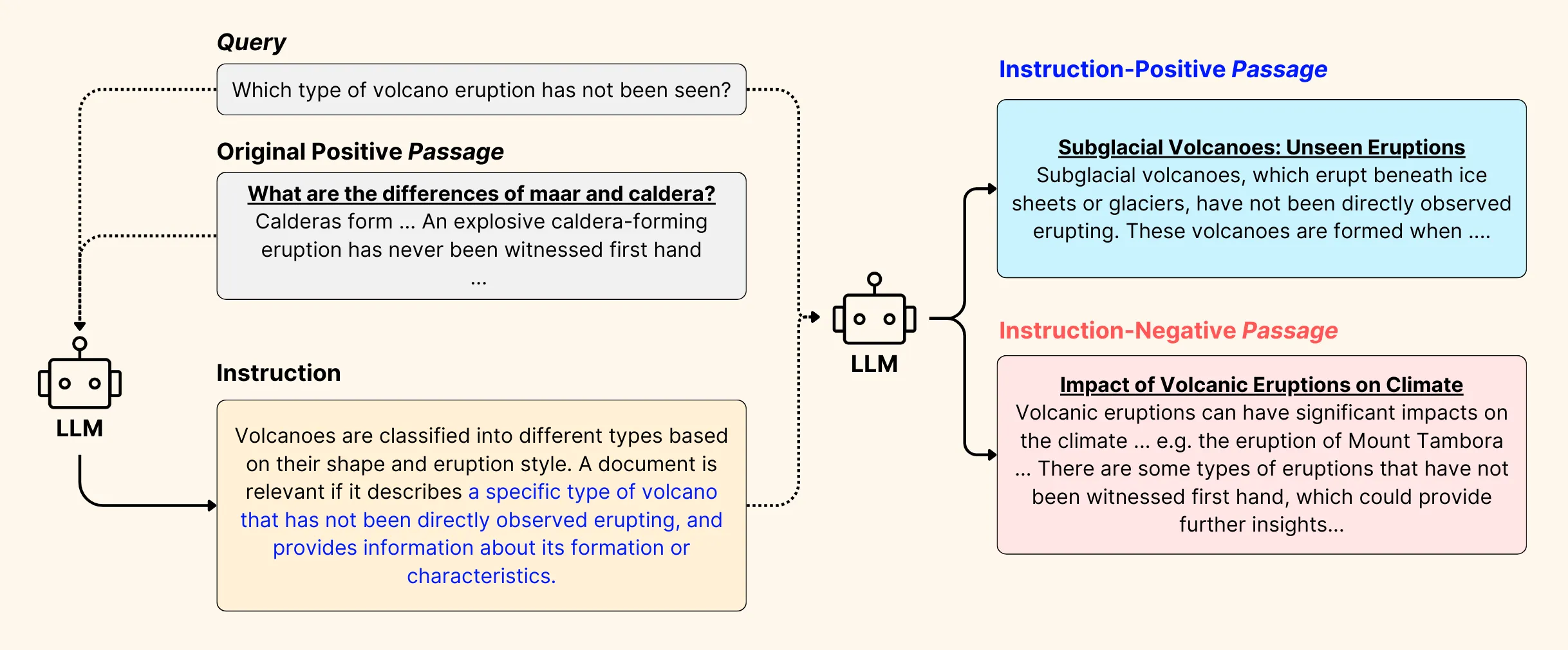
Figure 2: Data generation process for Promptriever.
To achieve this, for the publicly released version of Promptriver, we created a synthetic data generation process that starts with the MS MARCO dataset1, which contains short queries together with their positive and negative passages mined from web searches.
Figure 2 presents a high-level sketch of our method. For a given short query and its positive passage from MS MARCO, we prompt an LLM to:
The quality of instruction-positive and instruction-negative passages was crucial for successful training, and we filtered them with additional criteria to ensure their accuracy. This results in a final dataset consisting of ~491,000 queries.
With this dataset, we then trained a LLaMA-pretrained model with Low-Rank Adaptation (LoRA), following the RepLLaMA recipe2.
We evaluate Promptriever extensively on datasets covering instruction following and both in-domain and out-of-domain text retrieval. We compare with the RepLLaMA model as a primary baseline given the shared backbone model, and also include other state-of-the-art retrieval models.
Our experiments demonstrate that:
• Promptriever achieves state-of-the-art instruction-following capabilities. As shown in Figure 3, it outperforms other strong models by large margins on both the FollowIR and InstructIR datasets3,4. Compared to RepLLaMA, it demonstrates greater robustness against variations in query phrasing, improving robustness scores by nearly 13 points on InstructIR.
• Promptriever demonstrates stronger out-of-domain (OOD) retrieval performance. Figure 4 illustrates how Promptriever compares against RepLLaMA and BM25 on the popular BEIR benchmark covering a diverse set of text domains. Note that the strong OOD performance is purely due to instruction training, as we never trained explicitly with data from other domains.
• Promptriever maintains competitive in-domain retrieval performance. On the TREC DL20 retrieval evaluation, Promptriever scores 72.3 nDCG@10 compared to 71.8 from RepLLaMA.
For more detailed ablation studies and analysis, please refer to the Promptriever paper.

Figure 3: Instruction following evaluation results on the FollowIR and InstructIR datasets. Higher is better for all metrics. Gecko model results are from a proprietary API and not included for InstructIR.
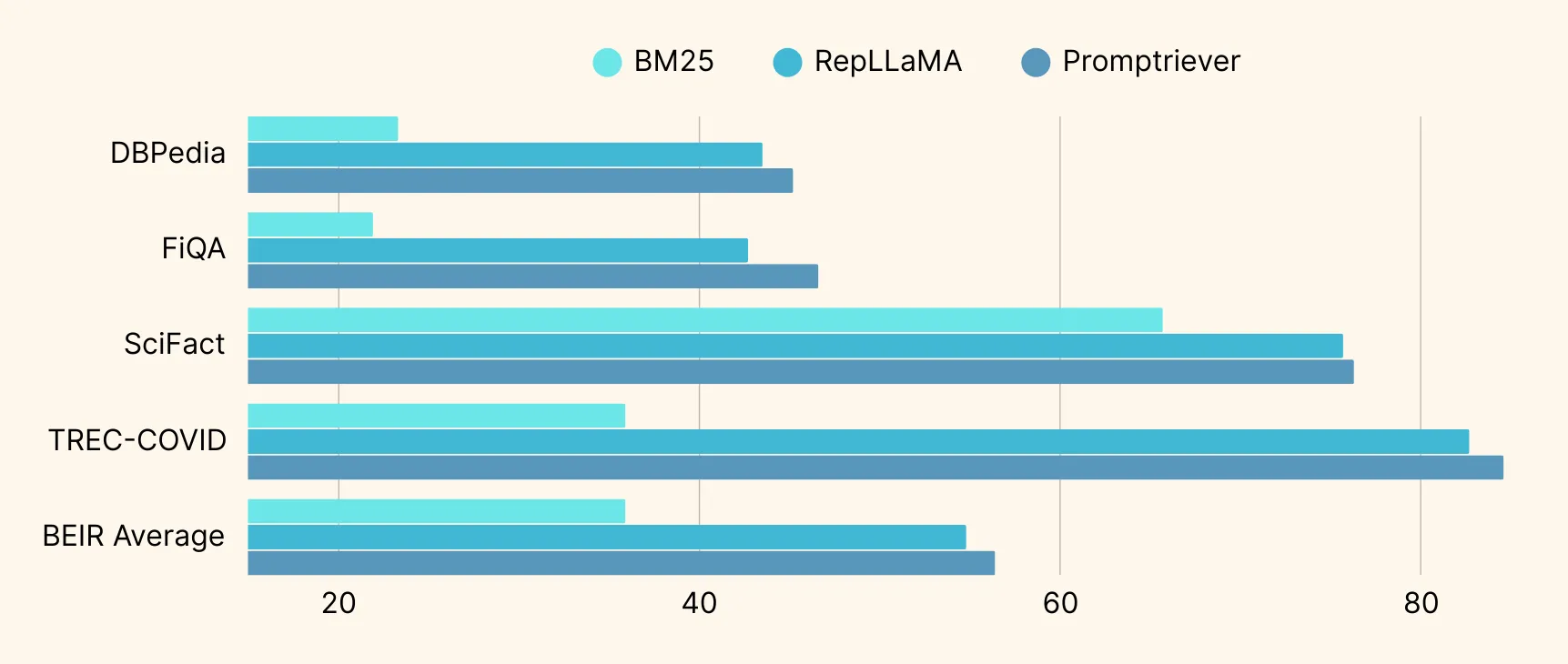
Figure 4: Out-of-domain retrieval evaluation on the BEIR benchmark under the nDCG@10 metric.
Published at ICLR 2025, Promptriever is the first research work that elevates retrieval model’s performance on queries with complex instructions. It opens up new possibilities to build retrieval systems that understand complicated user requirements without a complicated architecture.
To facilitate research work on this direction, we made available the following resources together with our paper:
Orion Weller led the work of Promptriever during his internship at Samaya AI, under the mentorship of Jack Hessel, Yuhao Zhang and Ashwin Paranjape. Other collaborators include Benjamin Van Durme and Dawn Lawrie from the John Hopkins University.
Special thanks to members of the Samaya ML team, including Fabio Petroni, Michele Bevilaqua, Christos Baziotis and Roberto Dessi for their feedback on the research work, and Ashwin for his feedback on this blog post.
[1] MS MARCO is a large-scale dataset widely used for training and evaluating text retrieval and question answering systems.
[2] Our retrieval model is built on the idea and training recipe of RepLLaMA, a retrieval model fine-tuned on top of the LLaMA-2 pretrained weights. We use RepLLaMA as a primary baseline for comparison across the work.
[3] FollowIR and InstructIR are recently published benchmarks for evaluating retrieval models’ abilities at understanding queries with complex instructions and context.
Experience how Samaya can supercharge financial workflows
Get a DemoWe're backed by Gen AI leaders
The Expert AI Agent Platform Defining
Modern Finance
© 2026 Samaya AI. All Rights Reserved.


"We’ve spoken to ~40 companies offering AI in finance solutions, and done pilots with 10-15. Yours is the only tool that analysts are actively asking for, and saying how useful they find it."
Top 5 Hedge Fund